SPEECH RECOGNITION – 21125
The human voice consists of audio-frequency (AF) energy, with components ranging from about 100 Hz to several kilohertz (kHz). (A frequency of 1 Hz is one cycle per second; 1 kHz = 1000 Hz.) This has been known ever since Alexander Graham Bell sent the first voice signals over electric wires.
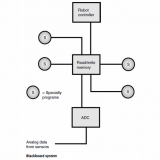
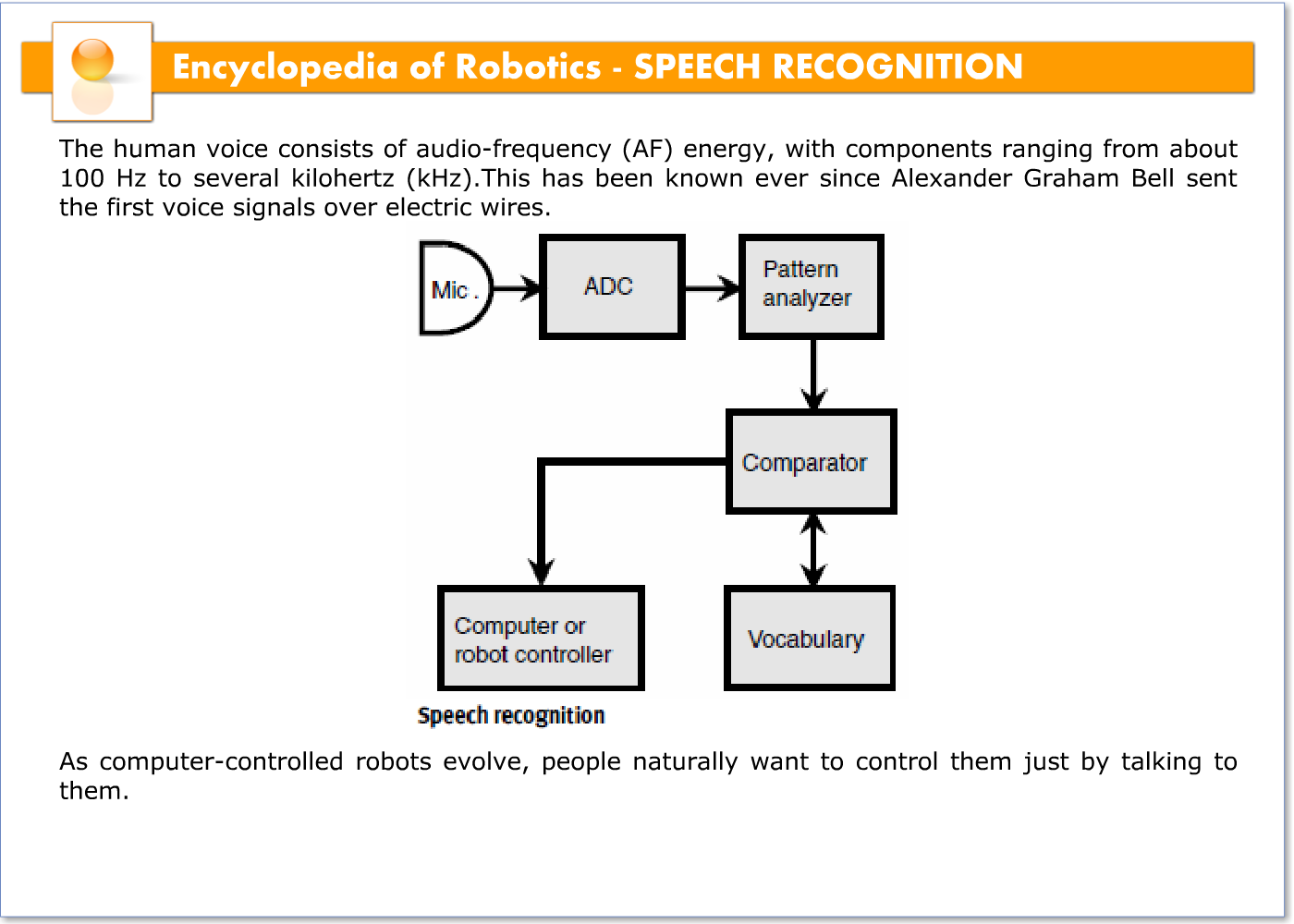
As computer-controlled robots evolve, people naturally want to control them just by talking to them. Speech recognition, also called voice recognition, makes this possible. The illustration is a block diagram of a simple speech-recognition system.
Components of speech
Suppose you speak into a microphone that is connected to an oscilloscope, and see the jumble of waves on the screen. How can any computer be programmed to make sense out of that? The answer lies in the fact that, whatever you say, it is comprised of only a few dozen basic sounds called phonemes. These phonemes can be identified by computer programs.
In communications, a voice can be transmitted if the bandwidth is restricted to the range from 300 to 3000 Hz. Certain phonemes, such as “ssss,” contain energy at frequencies of several kilohertz, but all the information in a voice, including the emotional content, can be conveyed if the audio passband is cut off at 3000 Hz. This is the typical voice frequency response in a two-way radio.
Most of the acoustic energy in a human voice occurs within three defined frequency ranges, called formants. The first formant is at less than 1000 Hz. The second formant ranges from approximately 1600 to 2000 Hz. The third formant ranges from approximately 2600 to 3000 Hz. Between the formants there are spectral gaps, or ranges of frequencies at which little or no sound occurs. The formants, and the gaps between them, stay in the same frequency ranges no matter what is said. The fine details of the voice print determine not only the words, but all the emotions, insinuations, and other aspects of speech. Any change in “tone of voice” shows up in a voice print. Therefore, in theory, it is possible to build a machine that can recognize and analyze speech as well as any human being.
A/D Conversion
The passband, or range of audio frequencies transmitted in a circuit, can be reduced greatly if you are willing to give up some of the emotional content of the voice, in favor of efficient information transfer. Analog-to-digital conversion accomplishes this.An analog-to-digital converter (ADC) changes the continuously variable, or analog, voice signal into a series of digital pulses. This is a little like the process in which a photograph is converted to a grid of dots for printing in the newspaper. There are several different characteristics of a pulse train that can be varied. These include the pulse amplitude, the pulse duration, and the pulse frequency.
A digital signal can carry a human voice within a passband less than 200 Hz wide. That is less than one-tenth of the passband of the analog signal. The narrower the bandwidth, in general, the more of the emotional content is sacrificed. Emotional content is conveyed by inflection, or variation in voice tone.When inflection is lost, a voice signal resembles a monotone. However, it can still carry some of the subtle meanings and feelings.
Word analysis
For a computer to decipher the digital voice signal, it must have a vocabulary of words or syllables, and some means of comparing this knowledge base with the incoming audio signals. This system has two parts: a memory, in which various speech patterns are stored; and a comparator, which compares these stored patterns with the data coming in. For each syllable or word, the circuit checks through its vocabulary until a match is found. This is done very quickly, so the delay is not noticeable. The size of the computer’s vocabulary is related directly to its memory capacity. An advanced speech-recognition system requires a large amount of memory.
The output of the comparator must be processed in some way, so that the machine knows the difference between words or syllables that sound alike. Examples are “two/too,”“way/weigh,” and “not/knot.” For this to be possible, the context and syntaxmust be examined. There must also be some way for the computer to tell whether a group of syllables constitutes one word, two words, three words, or more. The more complicated the voice input, the greater is the chance for confusion. Even the most advanced speech-recognition system makes mistakes, just as people sometimes misinterpret what you say. Such errors will become less frequent as computer memory capacity and operating speed increase.
Insinuations and emotions
The ADC in a speech-recognition system removes some of the inflections from a voice. In the extreme, all of the tonal changes are lost, and the voice is reduced to “audible text.” For most robot-control purposes, this is adequate. If a system could be 100 percent reliable in just getting each word right, speech-recognition engineers would be very pleased.However, when accuracy does approach 100 percent, there is increasing interest in getting some of the subtler meanings across, too. Consider the sentence, “You will go to the store after midnight,” and say it with the emphasis on each word in turn (eight different ways). The meaning changes dramatically depending on the prosodic features of your voice: which word or words you emphasize. Tone is important for another reason, too: a sentence might be a statement or a question. Thus, “You will go to the store after midnight?” represents something completely different from “You will go to the store after midnight!”Even if all the tones are the same, the meaning can vary depending on how quickly something is said. Even the timing of breaths can make a difference.